2026
Asynchronous LLM Reinforcement Learning Under Constrained Hardware
A from-scratch AReaL-style async RL system for Qwen 2.5-0.5B on 2 V100 GPUs, studying bounded staleness, policy lag, and learning efficiency under constrained hardware.
- LLM systems
- reinforcement learning
- distributed training
- infrastructure
{kind=link}

Overview
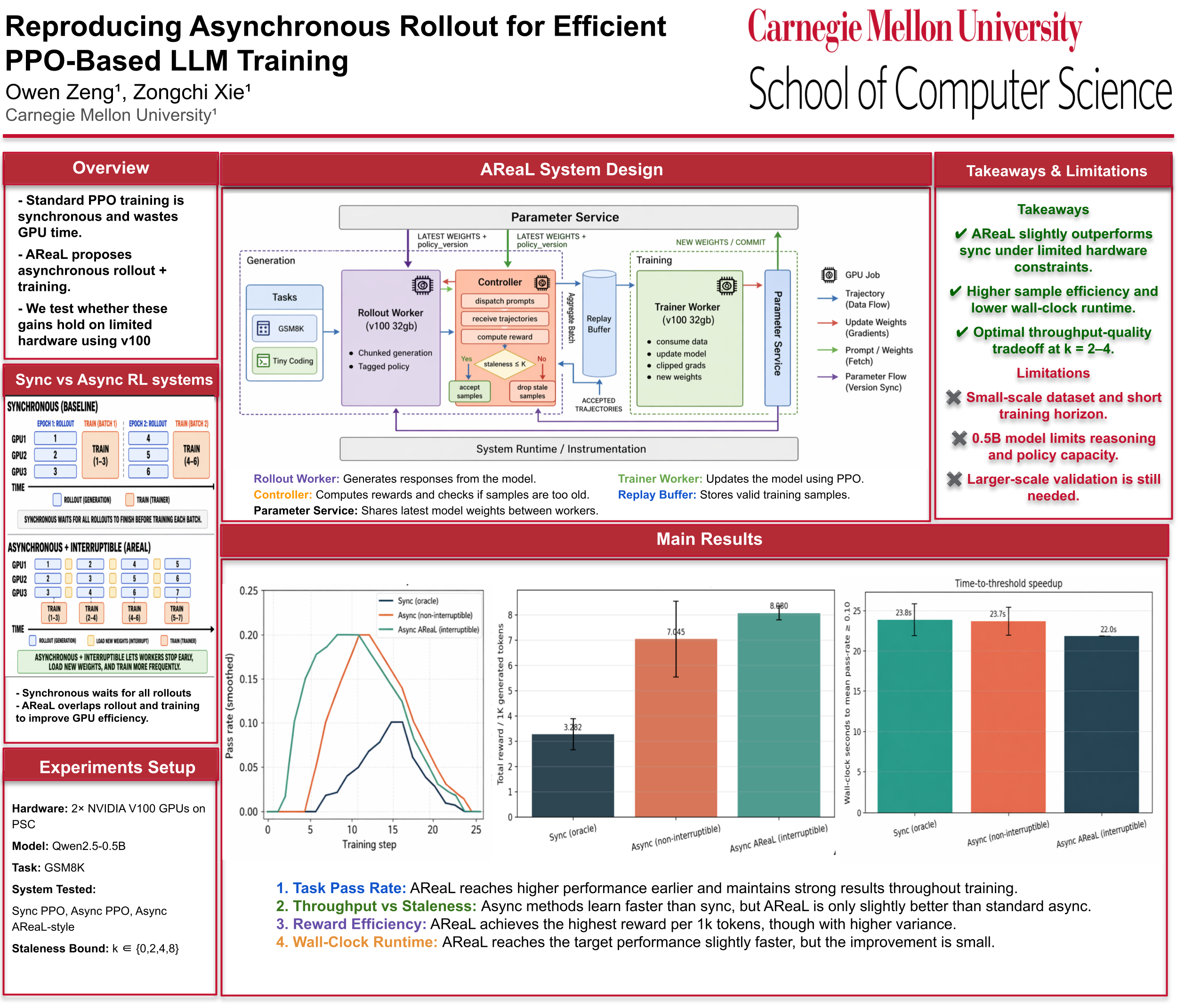
Implemented a lightweight asynchronous reinforcement-learning system inspired by AReaL to test whether large-scale rollout/training overlap ideas transfer to a small 2x V100 setting with limited data and no modern BF16 or optimized attention-kernel assumptions.
Problem
Large-scale LLM RL systems often rely on many workers, modern inference backends, and enough parallelism to hide training and generation costs. The project asks what remains useful when the system is constrained to commodity V100 hardware, limited overlap, and shorter experiment horizons.
What I Built
- An AReaL-style multiprocessing topology with controller, rollout worker, trainer worker, parameter service, policy-version clock, and bounded-staleness replay filtering.
- Matched synchronous, threaded-async, and AReaL-style runners sharing reward harnesses, tokenizer setup, logging, and model backends for apples-to-apples comparison.
- A real GRPO/PPO update path with group-normalized rewards, clipped surrogate objective, KL penalty, gradient clipping, token-length normalization, and decoupled-objective ablation.
- Experiment automation and plotting that regenerate pass-rate curves, time-to-threshold plots, staleness distributions, throughput views, and report tables with crash-resume support.
Technical Stack
- Python
- PyTorch
- Hugging Face Transformers
- Qwen 2.5-0.5B-Instruct
- multiprocessing
- CUDA / V100
- GSM8K
- Slurm
- Pandas
- Matplotlib
Results / Outcomes
- Showed that bounded staleness is a useful control knob: stricter freshness reduces accepted throughput, while moderate staleness around K=2-4 gave the best quality-efficiency tradeoff.
- AReaL-style async reached useful performance earlier and achieved the strongest sample efficiency in the report summary, but did not consistently reduce total end-to-end runtime at this scale.
- Found that the decoupled objective underperformed naive PPO in the constrained regime, highlighting that objective-level gains are more scale-sensitive than the system topology.
- Documented engineering lessons around CUDA multiprocessing, worker-ready barriers, policy-version flow, crash-resumable sweeps, and stable V100 execution.